Linux-进程
本文最后更新于:9 天前
Basic knowledge about OS && Linux. Solutions about MIT 6.828
进程
进程模型
进程是一个正在执行程序的实例,包括了程序代码和它当前的状态(寄存器…)
一个进程包括三个部分
Tips: The differences between process and program
Program is just the static text
Process is an dynamic entity being executed and has lifecycle
So if a program exec two times ,there should be two processes
进程的创建
四种事件会导致进程的创建:
1.系统初始化
2.正在运行的程序执行了创建进程的系统调用
3.用户请求创建一个新进程
4.批处理作业的初始化
新进程都是由一个已存在的进程执行了一个用于创建进程的系统调用而创建。
在Linux中,只有fork这个系统调用可用来创建进程。
fork后,创建的子进程会和父进程拥有相同的内存映像、环境变量。通常,子进程会接着执行一个execve之类的系统调用来修改内存映像从而运行一个新的程序。
进程的终止
进程终止的条件:
1.正常退出(自愿的)
2.出错退出(自愿的) 自愿时通常调用exit系统调用
3.严重错误(非自愿)
4.被其他进程杀死(非自愿)//在Linux和Windows中,如果一个进程被杀死,但他创建的进程不会被全部杀死
进程的状态
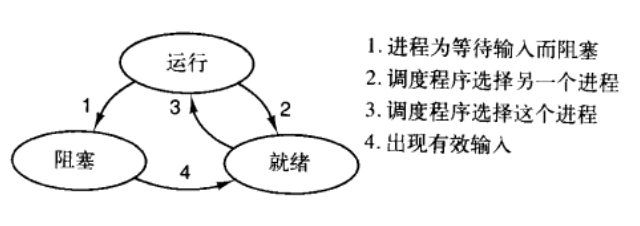
处于阻塞状态的进程不会参与进程调度,处在运行和就绪状态的进程会在就绪队列中。
Running->Block:进程需要等待数据(自发)
Running->Ready:调度程序造成(优先级调度、时间片流转…)
Ready->Running:调度程序造成
Block->Ready:1.进程发起。2.OS发起。
进程的生命周期
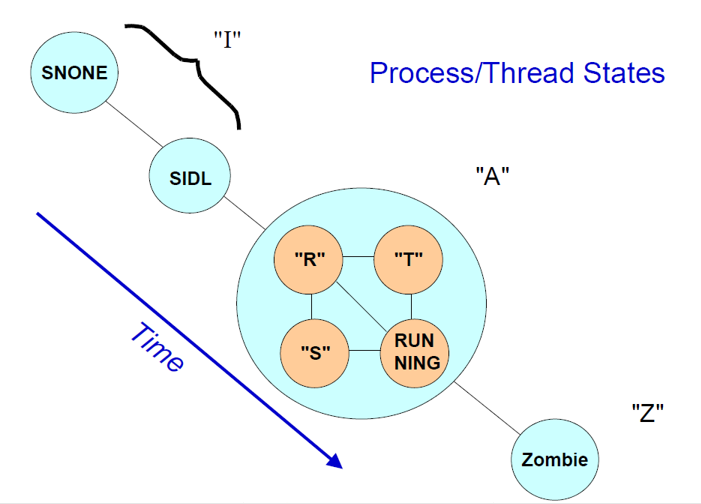
I (Idle) state(空闲状态)
进程在被创造前需要在进程/线程表中申请一个空间,这时处于SNONE状态
进程正在被创作时,需要向内存申请存储空间,此时处于SIDL状态。
A (active) state(活跃状态)
当进程处于A状态时,他会有一个或多个线程处于R(ready to run)状态。这些线程必须和其他处于R态的线程共用CPU。CPU同时只能跑一个线程(不考虑多处理器)
当线程需要等待事件发生或者输入输出时,为了不浪费CPU,他会进入sleep状态并且放弃CPU使用权。当输入/输出结束,线程会被唤醒进入R状态。
线程可能会被一些信号终止或者开启。当线程被挂起时,他处于T状态,无法执行。
Z (zombie) state(僵尸状态)
当一个进程死亡(结束)时,他会变成僵尸进程。
僵尸进程除了进程/线程表外不占用其他资源。他只会存活很短的时间,直到他的父进程发出信号,清理进线程表。
但是当一个进程的父进程先于子进程死亡时/或者无法发出信号时,就会在OS中留下僵尸进程。
如果OS长时间运行,进程表可能会被僵尸进程塞满,无法再开启新的进程(重启系统)。
线程
我们为什么需要线程?
进程模型的抽象让我们不必再考虑CPU中断,时钟周期,上下文切换之类的底层内容,只要考虑并行进程即可。
但对于很多进程来说,他们还需要一种能够共享存储空间与数据的能力(例如word文档,他需要有定时保存,同时修改多页内容等功能)
而且使用线程后可以将某些阻塞的活动(IO)的时间用来进行其他功能,可增大CPU利用率。
而且线程相对于进程来说是一个更加轻量级的模型,更容易被创建、结束。
典型的例子就是word、web服务器…
在没有多线程的情况下,我们通过有限状态机这样的设计实现Web服务器
即使用非阻塞版本的系统调用来进行IO,再有需求进来时,会进行新工作。
在这种设计中,“顺序进程”模型消失了,但进程每次切换工作时都要将先前内容进行存储。
可以认为我们模拟了线程及其堆栈。
| 模型 | 特性 |
|---|---|
| 多线程 | 并行、阻塞系统调用 |
| 单线程进程 | 无并行性、阻塞系统调用 |
| 有限状态机 | 并行性、非阻塞系统调用、中断 |
经典线程、POSIX线程
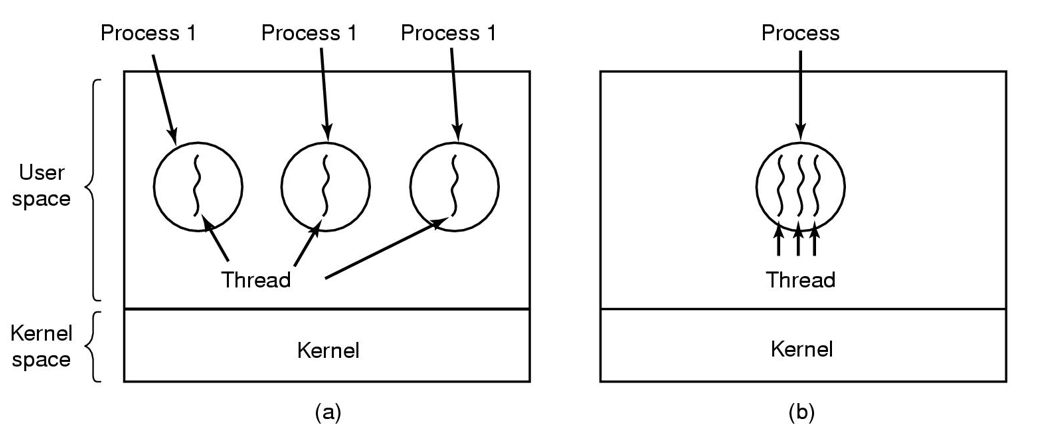
在图a中可以看到三个传统的进程,每个进程有自己的地址空间和一个控制线程。
图b中可以看到一个进程拥有三个控制线程,且运行在同一地址空间。
在多线程进程中,所有线程都共享完全一样的地址空间,也就是共享同样的全局变量,且线程之间是不存在保护的。

上图给出了进线程中所包含的内容。
有了线程的概念后,可以把进程当作资源管理的单位,线程当做执行的单位。
每个线程都有自己的堆栈
假设有下面这样的情况:过程X调用Y,Y调用Z,当Z执行时,XYZ使用的栈帧都会存在堆栈中。而每个线程往往会执行不同的过程,这就让他们有各自不同的历史,也就是每个线程都要有自己的堆栈。
线程也可以创造线程,且线程间一般不会存在父子关系
POSIX线程
通过一个求PI的程序来说明。
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <time.h>
double PI;
long num_thread;
long N;
double tim;
pthread_t* threads;
pthread_mutex_t lock;
void* thread(void* ID)
{
long id=(long)ID;
int length=N/num_thread;
int i;
pthread_mutex_lock(&lock);
for(i=id*length;i<(id+1)*length;i++)
{
PI+=(4.0/N)*(1.0/(1+((i+0.5)/N)*((i+0.5)/N)));
}
pthread_mutex_unlock(&lock);
}
int main()
{
printf("Please input the num of threads\n");
scanf("%ld",&num_thread);
printf("Please input the N of calculator\n");
scanf("%ld",&N);
clock_t start,end;
start=clock();
threads=(pthread_t*)malloc(sizeof(pthread_t)*num_thread);
long i;
for(i=0;i<num_thread;i++)
{
pthread_create(&threads[i],NULL,thread,(void*)i);
}
for(i=0;i<num_thread;i++)
{
pthread_join(threads[i],NULL);
}
end=clock();
tim=(double)(end-start)/CLOCKS_PER_SEC;
printf("Running Time: %fs\n",tim);
printf("PI= %.15f\n",PI);
return 0;
}
在用户/内核中实现线程
1.在用户空间实现线程
此时内核并没有线程的概念,他仍然只会对进程进行调度。此时线程的实现需要用户级程序去完成。
其实现大都使用pthread的系统调用。
同时,在用户空间管理线程时,每个进程也要有对应的线程表来记录进程中的线程。
优点:
1.线程间切换很快
当一个线程引发了自己的阻塞,那么他就会存储自己的状态,并在线程表中查看可运行的线程,将新线程的保存值重新装入机器的寄存器中。
因此,只要堆栈指针和程序计数器一被切换,新的线程就会自动运行。
这样的切换要比陷入内核来说更快。
2.每个进程可以有自己的调度算法,且扩展性强
可让用户程序自定义线程的运行状态。内核线程需要一些固定的表格空间和堆栈,如果内核线程数量很大就会出现问题。
缺点:
1.如何实现阻塞系统调用
线程的目标是允许每个线程使用阻塞调用,且要避免被阻塞的线程影响其他线程。
2.starvation问题
如果一个线程开始运行,那么在该进程中的其他线程都无法运行。除非该线程主动放弃CPU。
由于在进程中不会有中断的概念,所以无法使用轮转调度的方法调度线程。
3.最大问题出现在本身
程序员通常会在经常发生线程阻塞的应用中才希望使用多线程。
但在一个服务器中,线程一直在进行着系统调用,如果原有线程阻塞,就很难让内核进行线程切换。否则就一直使用select系统调用。
但这样的话多线程的意义就不大了,并没有什么实质性的好处。
调度程序(Important)
在计算机中,如果有多个进程处于就绪状态,而只有一个CPU可用,那么OS就必须对下一个要运行的进程进行选择。完成这个工作的就是调度程序。
早期的批处理系统中的调度程序就是:顺序执行磁带上的每一个作业。由于那时CPU是稀缺资源,所以调度程序的作用十分重要。
但随着PC的普及以及CPU速度的快速增长,OS中多数时间只有一个活动进程,而且时间大多花费在等待用户输入,而非等待CPU计算。
但在Web服务器中,经常会有多个进程抢占CPU,此时的调度程序又十分重要。
为什么要好的调度程序?
因为进程切换的代价是十分高昂的:要先从用户态切换到内核态;保存进程状态;调度选择新进程;将新进程的内存印象装入MMU,开始运行。
如果调度程序每秒切换进程次数太多,会耗费大量CPU时间。
何时调度进程?
1.在创建一个新进程后,需要决定是运行父进程还是子进程
2.在一个进程退出时必须调度
3.进程阻塞时必须调度
4.一个IO中断发生时必须调度
调度算法分类及其目标
对于所有系统,使用调度程序的目标都是要实现:公平(每个进程有公平的CPU份额)、策略强制执行(规定的策略被执行)、平衡(系统的所有部分都忙碌)
在不同系统中,需要的调度程序的类型、目标也不同,可划分为三组环境:
1.批处理(Batch System)
其目标要实现:吞吐量、周转时间、CPU利用率的最优。
2.交互式(Interactive System)
其目标为:实现响应时间、均衡性的最优。
3.实时(Real-time System)
其目标为:满足截止时间(避免丢失数据)、可预测性
批处理系统中的调度(Important)
先来先服务
按照进程请求CPU的顺序来使用CPU。类似于队列的FIFO机制,优点在于公平且思路简单。
但缺点也很明显:护航效应。
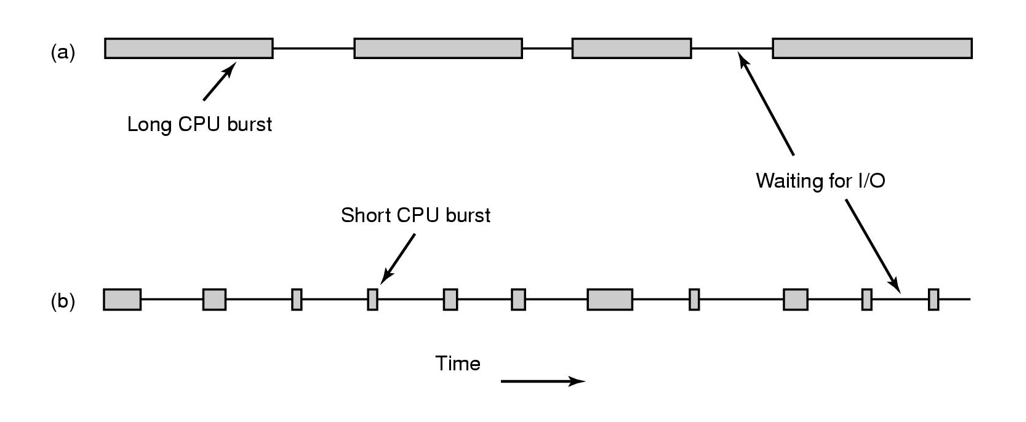
假如此时有一个CPU密集型和一个IO密集型的进程在就绪队列中,CPU密集型的进程在CPU中执行一段时间,进入IO;此时IO密集型进程进入CPU,执行很短很短的时间也进入IO;此时CPU空闲,CPU密集型进程再次进入就绪队列,IO进程又会等待CPU密集型进程完成。
可以看到,在这种情况下,IO进程总是在等待着计算密集型进程使用完CPU,从而导致运行时间很长。
如果有可能让IO进程直接单独抢占一段时间,那么运行时间会大大减少。
可通过下图理解进程执行的过程,并不是一直使用CPU然后一直使用IO就结束了,而是交错着的
最短作业优先
由于需要知道运行时间,因此多用于专用OS,但可能出现starvation问题
最短剩余时间优先
由于需要知道剩余运行时间,只能在专用OS使用
高响应比优先
响应比的计算:Response Radio = Turnaround time / Executing time = 1 + Waiting Time/ Executing Time
例题
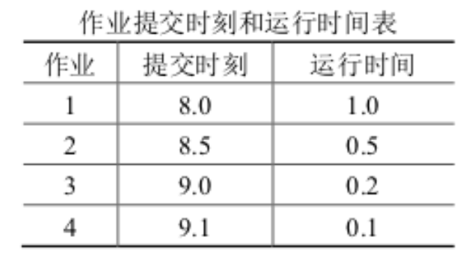
在一单道批处理系统中,一组作业的提交时刻和运行时间如下表所示。试计算一下三种作业调度算法的平均周转时间 T 和平均带权周转时间 W。 (1) 先来先服务; (2) 短作业优先 (3) 高响应比优先。作业提交时刻和运行时间如下表
1.先来先服务
根据题目可得到以下数据
| 作业 | 提交时刻 | 运行时间 | 开始时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|
| 1 | 8.0 | 1.0 | 8.0 | 9.0 | 1.0 | 1.0 |
| 2 | 8.5 | 0.5 | 9.0 | 9.5 | 1.0 | 2.0 |
| 3 | 9.0 | 0.2 | 9.5 | 9.7 | 0.7 | 3.5 |
| 4 | 9.1 | 0.1 | 9.7 | 9.8 | 0.7 | 7.0 |
所以平均周转时间T=(1.0+1.0+0.7+0.7)/4=0.85
平均带权周转时间W=(1.0+2.0+3.5+7.0)/4=3.375
2.短作业优先
可知在8.0时系统中只有作业1,所以作业1仍为第一个执行的。
作业1执行完成时间为9.0
此时系统中有作业2,3两个作业,短作业优先选择作业3
作业3执行完成时间为9.2
此时系统中有作业2,4两个作业,短作业优先选择作业4
作业4执行完成时间为9.3
此时只有作业2
作业2执行完成时间为9.8
表格如下
| 作业 | 提交时刻 | 运行时间 | 开始时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|
| 1 | 8.0 | 1.0 | 8.0 | 9.0 | 1.0 | 1.0 |
| 3 | 9.0 | 0.2 | 9.0 | 9.2 | 0.2 | 1.0 |
| 4 | 9.1 | 0.1 | 9.2 | 9.3 | 0.2 | 2.0 |
| 2 | 8.5 | 0.5 | 9.3 | 9.8 | 1.3 | 2.6 |
可以得到
平均周转时间T=(1+0.2+0.2+1.3)/4=0.675
平均带权周转时间W=(1.0+1.0+2.0+2.6)/4=1.65
3.高响应比优先
同样8.0时系统只有作业1,执行作业1
作业1执行完成时间为9.0
此时系统中有作业2,3
此时作业2 response radio=(1+0.5/0.5)=2; 作业3 response radio=1
所以先执行作业2
作业2执行完成时间为9.5
此时系统中有作业3,4
此时作业3的response radio=(1+0.5/0.2)=3.5
作业4的response radio =(1+0.4/0.1)=5
所以先执行作业4
作业4执行完时间为9.6
执行作业3
执行完成时间为9.8
可列为如下表格
| 作业 | 提交时刻 | 运行时间 | 开始时间 | 完成时间 | 周转时间 | 带权周转时间 |
|---|---|---|---|---|---|---|
| 1 | 8.0 | 1.0 | 8.0 | 9.0 | 1.0 | 1.0 |
| 2 | 8.5 | 0.5 | 9.0 | 9.5 | 1.0 | 2.0 |
| 4 | 9.1 | 0.1 | 9.5 | 9.6 | 0.5 | 5.0 |
| 3 | 9.0 | 0.2 | 9.6 | 9.8 | 0.8 | 4.0 |
可知平均周转时间T=(1+1+0.5+0.8)/4=0.825
平均带权周转时间W=(1+2+5+4)/4=3
区分一下带权周转时间和响应比的概念
二者虽然看上去计算公式相同,但他们的性质是不同的
带权周转时间是在调度完成后评价该调度程序的一个指标,是静态的
而响应比是作为调度的一个条件来使用的,每当调度一次后,每个作业的响应比都会变化。是动态的。
交互式系统中的调度(Important)
Round-robin scheduling (轮转调度)
这是最简单、公平、使用最广的调度算法.
每个进程被分配一个时间片,即允许该进程在该时间段中运行。如果进程在时间片结束时还在运行,那就夺走CPU分配给下一个进程。如果进程在时间片结束前就完成或者阻塞,CPU就立即进行切换。
调度程序要做的就是维护一个可运行程序列表,并对使用完时间片的程序进行调整。
唯一要考虑的就是时间片的长度
时间片太短会导致进程切换过于频繁,降低CPU效率。太长又会引起对短的交互请求的不响应。
常将时间片设置在20~50ms之间
Priority scheduling (优先级调度)
在Round-robin中,我们把每个进程都看作同等重要,而优先级调度就是要改变这种想法,给每个进程赋予一个优先级,优先级高的进程会先运行。
为了防止高优先级进程一直运行下去,调度程序可能在每个时钟中断时降低其优先级,如果有高于其的进程,就开始调度。
也可以给每个进程设置一个允许允许的最大时间片,超过时间片后次高级进程就会运行。
线程调度
用户态线程
内核并不知道线程的存在,因此还是会直接对线程使用调度程序。
此时由进程中的线程调度程序来决定线程的运行。由于这里面并不存在时钟中断,所以线程可以按其意愿任意运行直到进程时间用完。
内核线程
此时内核选择特定的线程运行,且不用考虑线程属于哪个进程。可以分配时间…
二者的差别主要在于性能。
用户级线程的切换只需要少量指令,但内核级线程切换需要上下文切换,修改内存,高速缓存…
但内核级线程如果阻塞,并不用直接将整个进程挂起。
另外,从A的线程切换到B的线程的代价高于在一个进程中切换线程,因此,在有多种选择的情况下,倾向于在相同进程中切换线程。
进程间通信(Inter Process Communication, IPC)
进程间往往需要相互传递信息(例如你使用shell中的管道,她将一个进程的输出传递给另一个进程)。
IPC的三个问题
- 一个进程如何把信息传递给另一个。
- 如何确保两个/多个进程在关键活动中不会出现交叉。(比如12306的购票系统)
- 如何确保多个进程之间有正确的执行顺序(一个更改数据的操作和一个print操作,当数据更改后再print才是正确的)
下面我们来解决这三个问题
基础概念(竞争条件&临界区)
竞争条件:多个进程读写某些共享数据,而最后的结果取决于进程运行的精确时序的情况。
我们要实现IPC就要思考如何避免竞争条件?
关键是使用一种方法来阻止多个进程同时读写共享的数据。即实现mutual exclusion(互斥):一个进程使用共享数据时,其他进程不能做同样的操作。
我们可以把阻止多进程同时读写共享数据的问题进行抽象,把对共享内存进行访问的程序片段称为临界区域/临界区(critical region)。
All we need to do is 是两个进程不可能同时处于临界区。
更进一步,为了确保进程能够正确且高效地协作,我们对于一个好的解决方法提出4个要求:
1)任何两个进程不能同时在临界区中
2)不对CPU的速度和数量做任何假设
3)临界区外运行的进程不得阻塞其他进程
4)不得使进程无限期等待进入临界区
忙等待(busy waiting)的互斥
本部分可行的解决方案都有一个特征:在无法进入临界区时,他们都会持续地占据CPU时间直到被调度(不会主动放弃)。所以称为busy waiting。
一、屏蔽中断
这是最简单粗暴的方法
对于单处理器来说,在进程进入临界区后立即屏蔽所有中断,在离开前打开中断是最直接的方法。因为屏蔽中断后,时钟中断也被屏蔽——CPU不会调度其他进程。
其缺点在于给了用户程序太大的权力,一旦一个进程不再打开中断,那么整个OS/多核中的一个核就会终止运行。
屏蔽中断对于OS来说很好,在更新数据时屏蔽中断可以确保短时间内完成,同时也确保执行的正确。
总的来说:屏蔽中断对OS来说很有用,但对于用户程序来说并不是一个明智的解决方法。
二、锁变量
一种软件解决方法。设置一个共享锁变量,进入临界区前要先开锁才能进入。
但这种解决方法是不行的,只是一个套娃的方法。设想下面的情况:
如果一个进程在读锁变量为0后,在准备将其设置为1之前被调度;新调度的进程将其设置为1,进入临界区。
此时再返回第一个进程,他也会将锁变量设为1,也进入临界区。
此时临界区中有两个程序。
So,这种方法只是转移了矛盾,并没有根本解决矛盾。
三、严格轮换法
int turn=0;
/*进程 0*/
while(true)
{
while(turn!=0)
critical_region();
turn=1;
noncritical_region();
}
/*进程 1*/
while(true)
{
while(turn!=1)
critical_region();
turn=0;
noncritical_region();
}功能描述: 进程0首先检查turn为0,进入临界区;进程1检查turn为0,执行循环一直检查turn直至为1.(busy waiting!)
但这种解法也是存在问题的。
如果进程0是一个临界区密集型进程,进程1是一个非临界区密集型进程。
当进程0结束临界区操作,将turn设置为1。进程0迅速完成非临界区操作,而进程1正在忙于非临界区操作。此时进程0无法进入临界区(此时turn==1),进程1也不进入临界区。
这就违背了前面4个要求中的第3个:进程0被在临界区外的进程1阻塞无法进入临界区。
说明在一个进程比另一个慢得多的情况下,该严格轮换法并不太好。
四、Peterson解法 (针对两个进程)
#define FALSE 0
#define TRUE 1
#define N 2 //进程数量
int turn; //轮到谁?
int interested[N]={0}; //所有值初始化为0
void enter_region(int process)/*进程号*/
{
int other; /*另一进程号*/
other=1-process;
interested[process]=TRUE; /*表示感兴趣*/
turn = process; /*设置标志*/
while(turn==process&&interested[other]==TRUE); /*空语句*/
}
void leave_region(int process) /*离开的进程*/
{
interested[process]=FALSE; /*离开临界区*/
}在进入临界区之前,各个进程使用自己的进程号(0/1)**调用enter_region()**。
在完成临界区操作后,**调用leave_region()**。
即当turn==自己 且 另一个进程没有离开临界区时,自己不能进入。
如果两个进程几乎同时调用enter_region, 但进程0比1先存turn,那么最后turn==1。此时进程0可以进入临界区,进程1只能等待。
Attention:enter_region中的 turn 和 interest 设置顺序不能颠倒
假设现在已经颠倒 变成酱紫 ↓↓↓
void enter_region(int process)/*进程号*/
{
int other; /*另一进程号*/
other=1-process;
turn = process; /*设置标志*/
interested[process]=TRUE; /*表示感兴趣*/
while(turn==process&&interested[other]==TRUE); /*空语句*/
}如果进程0在将turn设置为0后被调度,进程1发现进程0没有interested,进入临界区。
此时调度回进程0,进程0发现turn!=0, 进入临界区。
此时有两个进程同时在临界区里,so… 出问题了。
进一步,我们思考一下peterson算法背后的思想以及为什么交换顺序后就不行
peterson算法的思想就是:类似孔融让梨,使用一个数组来表达每个进程想进入临界区的意图。每个进程要先表明自己的意图。最后一个进程要“让梨”,即如果turn是自己且对方想进入临界区,那自己就等待,让对方使用。
那么我们交换顺序后,就会出现一种情况:对方还没来得及表明意图,另一个进程就抢先看自己让不让梨(有些虚伪的感觉),结果对方还没说话你就抢过来话筒当然就不用让了,直接进入临界区。但此时对方却认为另一个人会让梨,于是自己也进入临界区。
so…. 就出现了如此的尴尬局面。
五、TSL指令
这是一种硬件支持方案
TSL RX, LOCK称为测试并加锁(test and set lock) 是一个原语操作,作用是将一个内存字lock读到寄存器RX中,同时写lock=1。然后在该内存地址上存一个非零值。
执行TSL指令的CPU将锁住内存总线,禁止其他CPU在本指令结束前访问内存。
enter_region:
TSL REGISTER,LOCK |复制锁到寄存器并将锁设为1
CMP REGISTER,$0 |判断锁是否为0
JNE enter_region |若非0,说明锁已被设置,进入busy waiting的循环
RET
leave_region:
MOVE LOCK,$0 |锁中存0
RET |return与peterson的使用类似
在进入临界区前,调用enter_region,将导致busy waiting直到锁空闲为止。
在离开临界区时,调用leave_region,将lock设置为0;
在intel的指令集中也有这样的操作:XCHG
睡眠与唤醒(Sleep and wakeup)的互斥
peterson算法和TSL解法都是正确的,但他们都有忙等待的缺点——不仅会浪费时间,还会可能引起意外的结果。
设想一台计算机有两个进程:H与L,H优先级高于L。调度规则是:只要H处于就绪状态就可运行。若此时,L在critical region 那么H就处于就绪态,开始busy waiting。但由于H就绪时,L不会被调度(OS认为H就绪时就会运行,而且H优先级高于L,因此OS也不会主动对运行的H进行调度),L也就无法离开临界区。H将永远等待下去。
上述情况称为 优先级反转问题。
所以,我们需要一种新的不同于busy waiting的解决方案来进行IPC。
所以有了sleep和wakeup这几条IPC原语,他们在无法进入临界区时将阻塞而不是busy waiting
sleep是一个引起调用进程阻塞的系统调用,即背挂起,直到被其他进程唤醒。
wakeup就是唤醒的进程咯QWQ!
呜,2021/1/1日的早上图书馆是真没人啊,哈哈哈哈,好喜欢这种感觉!!!哈哈哈哈哈哈哈哈哈哈!
使用sleep和wakeup来解决一下生产者-消费者问题。
问题描述:两个进程共享一个公共的固定大小的缓冲区,其中一个是生产者:将信息放入缓冲区。另一个是消费者:从缓冲区中读取信息。
要解决的主要问题是当缓冲区已满,生产者无法在放入新数据,让他睡眠。当缓冲区为空时,消费者睡眠直到生产者向其中放入一些数据后再将其唤醒。
code here ↓↓↓
#define N 100
int count=0;
void producer(void)
{
int item;
while(TRUE){
item=produce_item();
if(count==N)
sleep();
insert_item(item);
count=count+1;
if(count==1)
wakeup(consumer);
}
}
void consumer(void)
{
int item;
while(TRUE){
if(count==0)
sleep();
item=remove_item();
count=count-1;
if(count==N-1)
wakeup(producer);
consume_item(item);
}
}但这里还是会有竞争条件的——因为没有对count访问加限制。设想下面这种情况:
缓冲区为空,消费者发现count==0,正准备sleep并叫醒生产者。但OS此时调度生产者,生产者产生数据,count=1。生产者认为消费者现在一定在sleep,于是wakeup他,但此时消费者并没有睡眠。所以造成了一个wakeup信号丢失。
当消费者下次运行时,直接睡眠,生产者在数据产生完后也睡眠。
emmm,他们就这样一起睡下去了。
一种简单的解决方法是给消费者加一个唤醒等待位。类似spooling,就是wakeup信号的一个存储区。
信号量(Semaphore)的互斥与同步
信号量是0或者大于0的整数。
信号量只能被PV操作控制 (初始化除外;即使只想要读信号量的值也要通过PV)
PV操作是原子操作
P操作检查信号量,若大于0则将其减1。若等于0,则进程睡眠,且此时P操作并未结束。
V操作对信号量的值增加1,若一个或多个进程在该信号量上睡眠,则挑选一个允许完成其P操作。
PV在sleep wakeup的实现
/*P operation*/
P(Semaphore S)
{
S=S-1;
if(S<0){
added to the semaphore's queue and sleep;
}
}
/*V operation*/
V(Semaphore S)
{
S=S+1;
if(S<0){
wake up waiting process in the semaphore's queue;
}
}PV在忙等待中的实现
/*P operation*/
P(Semaphore S)
{
while(!S>0)
yield the CPU;
S--;
}
/*V operation*/
V(Semaphore S)
{
S++;
}下面使用信号量来解决生产者消费者问题
#define N 100
typedef int semaphore;
semaphore mutex=1;
semaphore empty=N;
semaphore full=0;
void producer(void)
{
int item;
while(TRUE){
item=prodece_item();//产生数据
P(&empty); //空槽--
P(&mutex); //进入临界区
inster_item(); //数据放入临界区
V(&mutex); //离开临界区
V(&full); //满槽++
}
}
void consumer(void)
{
int item;
while(TRUE){
P(&full); //满槽--
P(&mutex); //进入临界区
item=remove_item(); //从缓冲区读出数据
V(&mutex); //离开临界区
V(&empty); //空槽++
consume_item(item); //处理数据
}
}注意,对full和empty的P操作必须在mutex之前
设想以下情况:假如生产者已经将缓存填满,若先对mutex进行P操作,在执行P(empty)会被阻塞,希望消费者唤醒它。但消费者先执行P(mutex)也被阻塞,此时二者都被阻塞。
但在V操作时,并没有先后顺序。
哲学家就餐问题(同步)
#define N 5 /*哲学家数目*/
#define LEFT (i+N-1)%N /*i的左邻居编号*/
#define RIGHT (i+1)%N /*i的右邻居编号*/
#define THINKING 0 /*哲学家在思考*/
#define HUNGRY 1 /*哲学家试图拿起叉子*/
#define EATING 2 /*哲学家进餐*/
typedef int semaphore;
int state[N];/*记录每位哲学家的状态*/
semaphore mutex=1;/*临界区互斥*/
semaphore s[N];/*每个哲学家一个信号量*/
/*检查哲学家是否可以就餐*/
void test(int i/*每个哲学家编号*/)
{
if(state[i]==HUNGRY&&state[LEFT]!=EATING&&state[RIGHT]!=EATING){
state[i]=EATING;
V(&s[i]);
}
}
/*拿叉子,一次拿两个*/
void take_forks(int i)
{
P(&mutex);
state[i]=HUNGRY;/*记录哲学家i处于饥饿状态*/
test(i); /*尝试获取两把叉子*/
V(&mutex);
P(&s[i]); /*得不到需要的叉子就阻塞*/
}
/*放下叉子*/
void put_forks(int i)
{
P(&mutex);
state[i]=THINKING;/*哲学家就餐完毕*/
test(LEFT);
test(RIGHT);/*检查左右是否可吃*/
V(&mutex);
}
/*主函数*/
void philosopher(int i)
{
while(true){
think();
take_forks(i);/*获取两把叉子或阻塞*/
eat();
put_forks(i);/*放回两把叉子*/
}
}读者—写者问题(互斥)
读者优先
解决多个进程读写数据的情况:读者无互斥,读写,写写,有互斥。
typedef int semaphore;
semaphore mutex=1;/*控制对reader的访问*/
semaphore database=1;
int reader=0;
void reader(void)
{
while(true)
{
P(&mutex);
reader++;
if(reader==1)//只需要让第一个读者获取数据库访问权限,其他读者仅需要reader++即可
P(&database);
V(&mutex);
read_database();
P(mutex);
reader--;
if(reader==0)
V(&database);
V(&mutex);
use_data();
}
}
void writer(void)
{
while(true)
{
P(&database);//写者只关心数据库权限是否拥有即可。
write_data();
V(&database);
}
}只需要让第一个读者获取数据库访问权限,其他读者仅需要 reader++ 即可。
而写者关心的问题就比较少了,只需要看是否有其他进程有数据库权限即可(写者和写者、读者间都要互斥)
写者优先
typedef int semaphore;
int rc=0;
int wc=0;
semaphore db=1;
semaphore rcmutex=1;
semaphore wcmutex=1;
semaphore readable=1;
void reader()
{
P(&readable);
P(&rcmutex);
if(rc==0) P(&db);
rc++;
V(&rcmutex);
V(&readable);
read_data();
P(&rcmutex);
rc--;
if(rc==0) V(&db);
V(&rcmutex);
}
void writer()
{
P(&wcmutex);
if(wc==0) P(&readable);
wc++;
V(&wcmutex);
P(&db);
write_data();
V(&db);
P(&wcmutex);
wc--;
if(wc==0) V(&readable);
V(&wcmutex);
}读写公平
typedef int semaphore;
int rc=0;
semaphore mutex=1;
semaphore db=1;
semaphore fair=1;
void reader()
{
while(true){
P(&fair);
P(&mutex);
if(rc==0) P(&db);
rc++;
V(&mutex);
V(&fair);
read_data();
P(&mutex);
rc--
if(rc==0) V(&db);
V(&mutex);
}
}
void writer()
{
while(true){
P(&fair);
P(&db);
write_data();
V(&db);
V(&fair);
}
}PV题
一、嗜睡的理发师
有一个理发师,一把理发椅和 N 把供等候理发的顾客坐的椅子。如果没有顾客,则理发师便在理发师椅子上睡觉;当一个顾客到来时,必须唤醒理发师进行理发;如果理发师正在理发时又有顾客来到,则如果有空椅子可坐,他就坐下来等,如果没有空椅子,他就离开。为理发师和顾客各编一段程序(伪代码)描述他们的行为,要求不能带有竞争条件。
typedef int semaphore;
int waiting=0;
int chair=N;
semaphore barber=0,customer=0,mutex=1;
void Barber()
{
while(true){
P(customer);//无顾客,则睡眠
P(mutex);
waiting--;
V(mutex);
V(barber);//一个理发师开始理发
cut_hair();
}
}
void Customer()
{
while(true){
P(mutex);
if(waiting<chair){
waiting++;
V(mutex);
V(customer);//唤醒理发师
P(barber);//没人理发,就睡
get_hair_cut();//理发
}else{
V(mutex);
}
}
}二、吸烟者问题
三个吸烟者在一间房间内,还有一个香烟供应者。为了制造并抽掉香烟,每个吸烟者需要三样东西:烟草、纸和火柴。供应者有丰富的货物提供。三个吸烟者中,
第一个有自己的烟草,第二个有自己的纸,第三个有自己的火柴。供应者将两样东西放在桌子上,允许一个吸烟者进行对健康不利的吸烟。当吸烟者完成吸烟后唤醒供应者,供应者再放两样东西(随机地)在桌面上,然后唤醒另一个吸烟者。试为吸烟者和供应者编写程序解决问题。
typedef int semaphore;
semaphore s=1;
semaphore s1=0,s2=0,s3=0;
bool material[3]={0};
void supply()
{
while(true){
P(s);
int i=rand()%3;
material[(i+1)%3]=1;
material[(i+3-1)%3]=1;
if(material[0]&&material[1])
{
V(s3);
}else if(material[0]&&material[2]){
V(s2);
}else{
V(s1);
}
}
}
void Smoker1()
{
while(true){
P(s1);
smoke();
V(s);
}
}
void Smoker2()
{
while(true){
P(s2);
somke();
V(s);
}
}
void Smoker3()
{
while(true){
P(s3);
somke();
V(s);
}
}三、面包师问题
面包师有很多面包和蛋糕,由 n 个销售人员销售。每个顾客进店后先取一个号,并且等着叫号。当一个销售人员空闲下来,就叫下一个号。请分别编写销售人
员和顾客进程的程序。
typedef int semaphore;
semaphore customer=0;
semaphore seller=n;
semaphore c_mutex=1;
semaphore s_mutex=1;
int number_c=0,number_s=0;
void Customer()
{
P(&c_mutex);
number_c++;
V(&c_mutex);
V(customer);
P(seller);
Buy and go ;
}
void Seller()
{
while(true){
P(&customer);
P(&s_mutex);
call the number_s customer;
number_s++;
V(&s_mutex);
V(&seller);
}
}四、水果!
桌上有一空盘,运行存放一只水果,爸爸可向盘中放苹果,也可放桔子,儿子专等吃盘中的桔子,女儿专等吃盘中的苹果。规定当盘中空时一次只能放一个水果供吃者取用,用 P,V 原语实现爸爸儿子和女儿 3 个并发进程的同步。
typedef int semaphore;
semaphore empty=0;
semaphore mutex=1;
semaphore apple=0;
semaphore orange=0;
void dad()
{
while(true){
P(&empty);
P(&mutex);
put_fruit();
V(apple or orange);
V(&mutex);
}
}
void son()
{
while(true){
P(&orange);
P(&mutex);
get orange!
V(&mutex);
V(&empty);
}
}
void daugther()
{
while(true){
P(&apple);
P(&mutex);
get apple!
V(&mutex);
V(&empty);
}
}五、仓库问题
有一个仓库,可以存放 A 和 B 两种产品,仓库的存储空间足够大,但要求:
( 1)一次只能存入一种产品( A 或 B);
( 2) -N < (A 产品数量-B 产品数量) < M。
其中, N 和 M 是正整数。试用“存放 A”和“存放 B”以及 P、 V 操作描述产品 A 与产品 B 的入库过程。
typedef int semaphore;
semaphore mutex=1;
semaphore a=M-1;
semaphore b=N-1;
void putA()
{
P(&a);
P(&mutex);
PUT IN THE STORAGE!
V(&mutex);
V(&b);
}
void putB()
{
P(&b);
P(&mutex);
PUT IN THE STORAGE!
V(&mutex);
V(&a);
}六、数字问题
三个进程 P1、 P2、 P3 互斥使用一个包含 N(N>0)个单元的缓冲区。 P1 每次用 produce()生成一个正整数并用 put()送入缓冲区某一空单元中;P2 每次用 getodd()从该缓冲区中取出一个奇数并用 countodd()统计奇数个数;P3 每次用 geteven()从该缓冲区中取出一个偶数并用 counteven()统计偶数个数。请用信号量机制实现这三个进程的同步与互斥活动,并说明所定义信号量的含义。要求用伪代码描述。
typedef int semaphore;
semaphore mutex=1;
semaphore empty=N;
semaphore even=0;
semaphore odd=0;
void P1()
{
while(true){
int data=produce();
P(&empty);
P(mutex);
PUT DATA!
V(&mutex);
if(data%2==0)
V(&even);
else
V(&odd);
}
}
void P2()
{
while(true){
P(&odd);
P(&mutex);
getodd();
V(&mutex);
V(&empty);
countodd();
}
}
void P3()
{
while(true){
P(&even);
P(&mutex);
geteven();
V(&mutex);
V(&empty);
counteven();
}
}七、窄桥问题
有桥如下图所示,
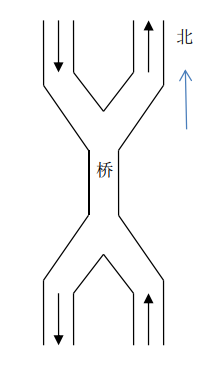
车流如箭头所示,桥上不允许两车交汇,但允许同方向多辆车依次通 过(即桥上可以有多个同方向的车)。用 P、V 操作实现交通管理以防止桥上堵塞。
typedef int semaphore;
semaphore bridge=1;
semaphore NS_mutex=1;
semaphore SN_mutex=1;
int NSC=0,SNC=0;
void N2S()
{
while(true){
P(&NS_mutex);
NSC++;
if(NSC==1) P(&bridge);
V(&NS_mutex);
GETTHROUGH!
P(&NS_mutex);
NSC--;
if(NSC==0) V(&bridge);
V(&NS_mutex);
}
}
void S2N()
{
while(true){
P(&SN_mutex);
SNC++;
if(SNC==1) P(&bridge);
V(&SN_mutex);
GETTHROUGH!
P(NS_mutex);
SNC--;
if(SNC==0) V(&bridge);
V(&NS_mutex);
}
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!